AI辅助开发,助力数智融合
发布时间: 2025-10-14
在现代软件开发中,开发效率和代码质量是每个团队关注的核心问题。随着项目复杂度提升,重复性工作和低价值任务占据了开发者大量时间。如何提升开发效率,同时保证代码质量?人工智能(AI)为我们提供了新的解决方案。
AI 辅助编程(AI-assistedcoding)通过智能化生成、补全和优化代码,让开发者从繁琐的重复性工作中解放出来,专注于更具创造性的任务。随着大语言模型(LLM)的发展,这一技术已经从科幻走入现实,从个人开发者的辅助工具发展为企业级生产力平台。
一、概念
AI 辅助编程是利用人工智能,尤其是大语言模型,在软件开发中提供智能化支持的技术。其核心能力主要包括:
- 代码生成:根据自然语言描述或功能需求,自动生成函数、模块甚至完整程序。
- 代码补全:在 IDE 中提供智能补全建议,帮助开发者快速写出高质量代码。
- 代码优化与重构:自动重构代码,提高可读性和性能,减少潜在错误。
- 自动化测试生成:根据功能描述或已有代码生成单元测试或接口测试,减少测试负担
二、技术原理与工作流程
技术基础:大语言模型(LLM)驱动
AI 辅助编程的核心依赖于大语言模型(LLM)及其训练与优化技术。模型通过理解编程语言的语法与语义,实现“自然语言 → 可执行代码”的转化,为开发者提供智能化编程支持。
- 主流模型与适配场景
常见的模型包括 GPT 系列、Codex、LLaMA 和 StarCoder 等,不同模型的适配场景各有侧重:GPT-4o/Codex 擅长‘自然语言→复杂代码’的转化(如多语言混合项目),StarCoder 因训练数据含大量开源代码,更适配开源项目的代码补全;LLaMA 则因开源属性,适合企业基于私有代码库做轻量化微调,避免核心数据泄露。
- 训练来源与优化方法
训练数据主要来自开源代码库(如 GitHub、StackOverflow)、开发文档、教程以及 API 示例,为模型提供丰富的编程知识。为了提升特定语言或企业项目的生成效果,模型通常会进行微调(Fine-tuning)或者采用提示工程(Prompt Engineering)例如通过‘角色设定 + 约束条件’设计提示,通过设计高质量的提示指令,进一步提高生成代码的准确性和实用性。
在实际使用中,AI 辅助编程的工作流程可以概括为四个步骤:开发者在 IDE 或辅助工具中输入功能描述或已有代码片段,模型会首先解析自然语言或代码,理解用户的意图和上下文。接着,模型基于上下文生成对应的代码片段或函数,并返回给开发者。最后,开发者对生成的代码进行审查、测试和修改,确保其符合项目需求和质量标准。这个流程形成了一个人机协作的闭环,既提升了开发效率,又保证了代码的可靠性。
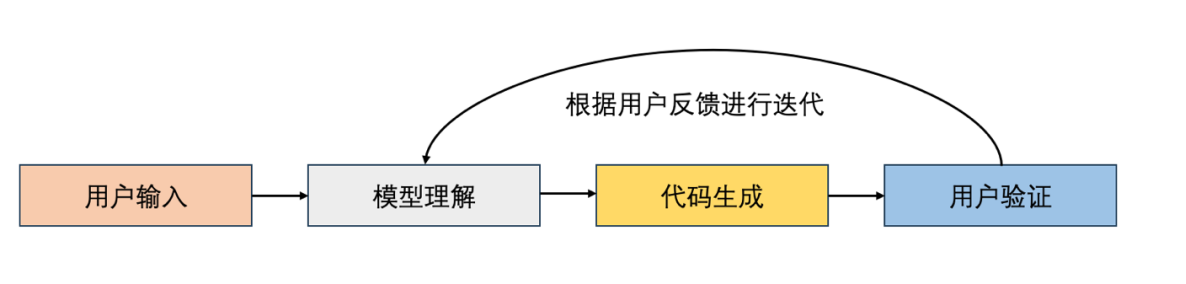
图 1 AI辅助编程工作流程
三、应用案例
在过去两年中,AI 辅助编程工具的发展非常迅速,其中最具代表性的莫过于 GitHub Copilot 和 Cursor。它们不仅能帮助开发者自动生成代码,还能理解上下文逻辑、优化结构、甚至协助调试。通过以下实际案例,可以直观感受到 AI 编程助手在真实开发场景中的价值。
案例一:企业客户数据管理
假设我们想快速做一个 面向企业客户数据管理的 AI 聊天助理,能够根据客户提问查询订单状态或库存信息。传统开发需要先学习前后端框架、API 调用方式和界面设计,还要手动调试接口,整个过程既繁琐又容易出错。使用 Cursor,我们只需在编辑器中输入自然语言指令:“帮我创建一个基于 Flask 的企业客户数据管理的 AI 聊天助理项目”,AI 工具即可生成完整、可运行的代码骨架,包括数据接口调用和前端交互模板,从而大幅缩短开发周期。
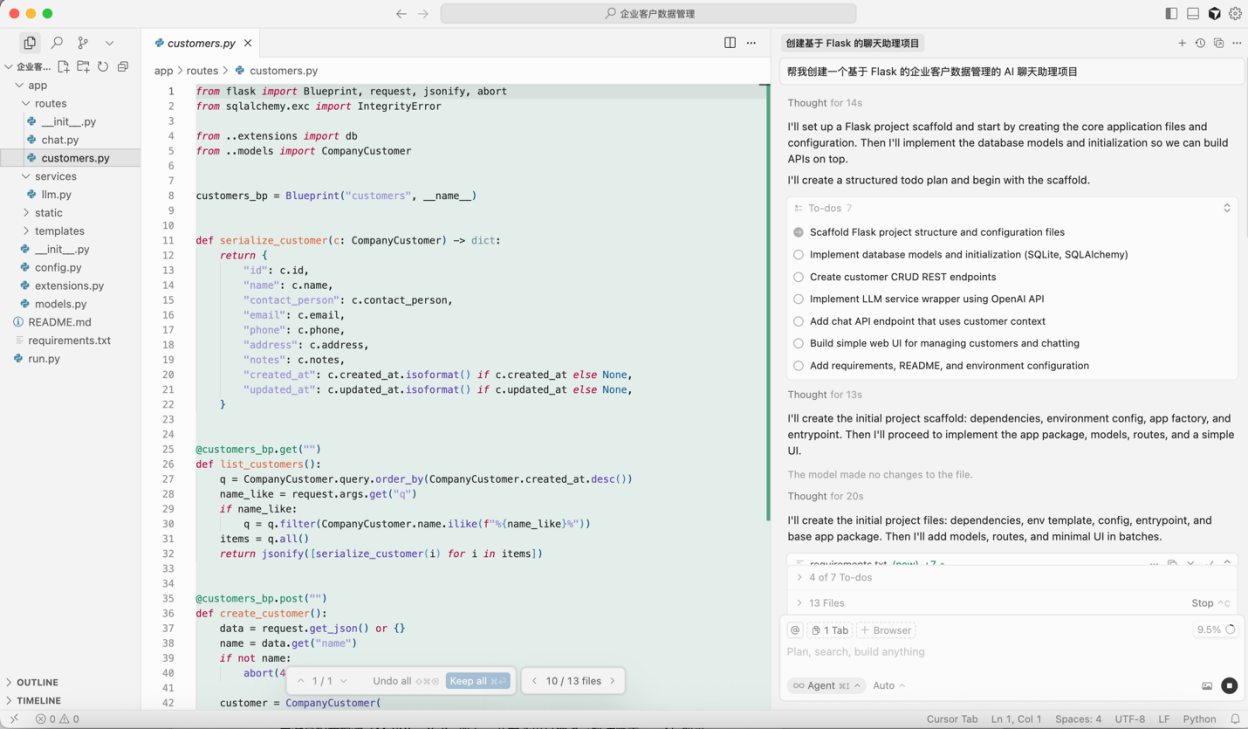
图 2 Cursor 生成企业客户数据管理系统代码
案例二:AI驱动的数据采集自动化
在传统的数据采集场景中,面对来自 MySQL、Kafka、API 接口、CSV 文件 等异构数据源,开发者往往需要手动编写不同的连接逻辑与数据提取脚本。例如,从 MySQL 拉取用户信息,再从 Kafka 消费实时日志,最后还要配置任务调度与异常监控。而借助 AI 工具,开发者只需用自然语言描述采集需求,例如:“请帮我从 MySQL 的用户表与 Kafka 的行为日志流中提取数据,合并后写入 Hive”。AI 即可自动生成一整套规范的 ETL 管道代码。
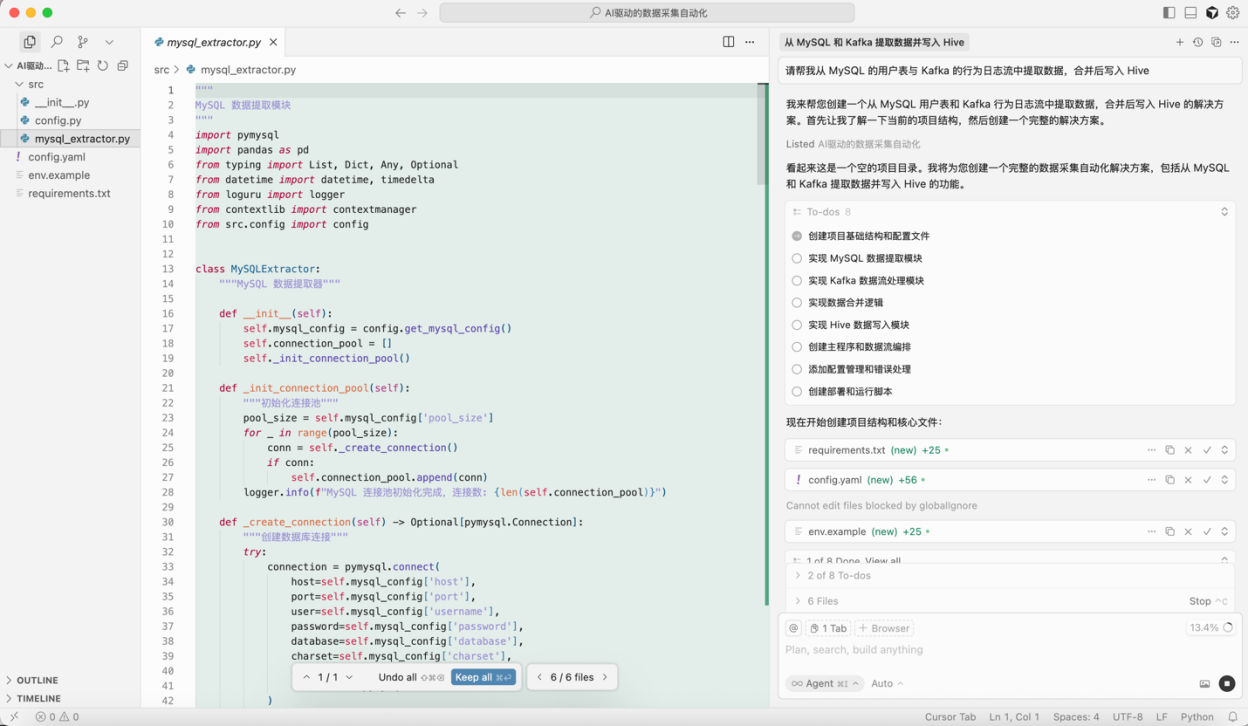
图 3 Cursor 生成数据采集代码
案例三:数据清洗与质量控制
在数据采集完成后,数据往往存在 缺失值、异常值、重复记录、字段格式不统一 等问题。以往开发者需要依靠手动编写 SQL 或 Python 脚本,逐步对不同类型的脏数据进行处理而借助 AI 辅助清洗能力,只需一句自然语言指令即可触发清洗逻辑,例如:“请检查 Hive 表中的异常值,填补缺失字段,并剔除重复数据”。AI 工具将自动生成并执行完整的数据清洗代码。这不仅提升了数据处理效率,也确保了数据的可用性与一致性,为后续分析建模打下坚实基础。
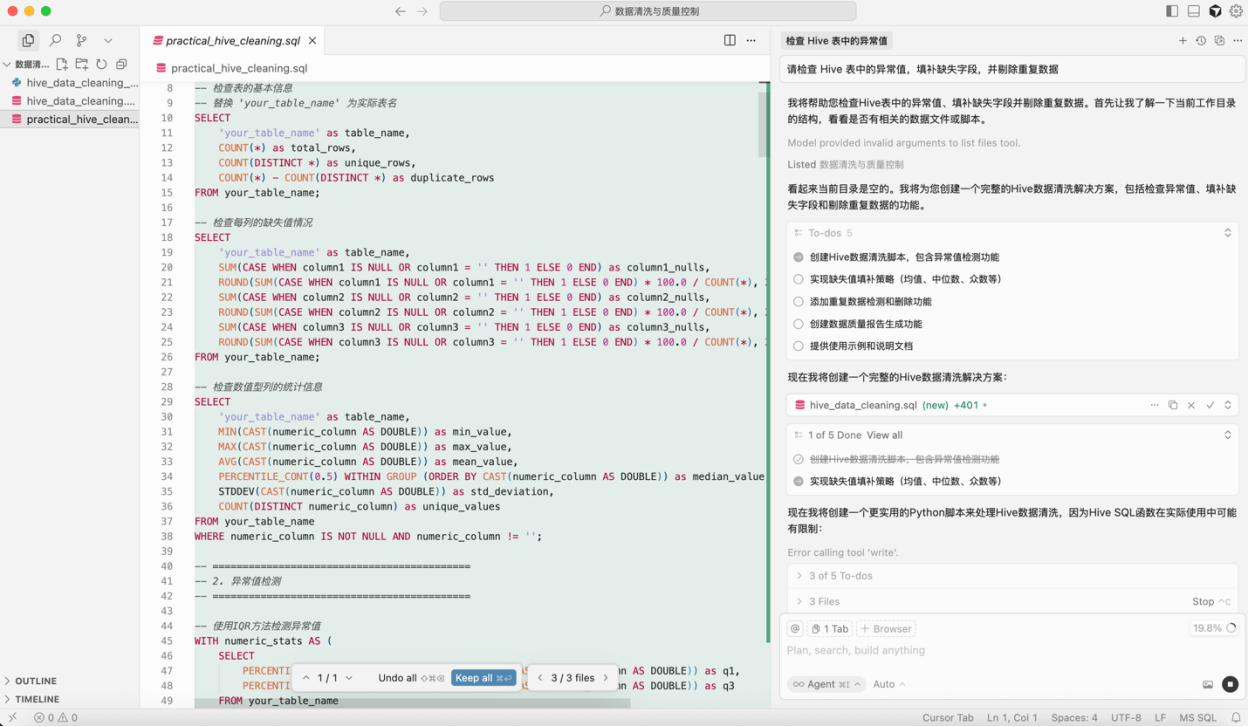
图 4 Cursor 生成数据清洗代码
上述案例展示了 AI 辅助编程在个人快速开发 demo 中的价值 —— 通过自然语言指令快速生成完整项目骨架,降低入门门槛。而在企业数智融合的核心场景(如数据治理)中,AI 辅助编程更能解决‘规模化编码、标准化落地’的痛点:面对多源数据接入、批量清洗、合规校验等重复性高、容错率低的任务,AI 可通过规范化代码生成,避免人工编码的效率低、误差高问题,推动数据治理从‘人工逐环节攻坚’转向‘AI 批量赋能’。
总结:
总体来说 AI 辅助编程以大语言模型(LLM)为核心,通过代码生成、补全、优化、自动化测试四大能力,在个人 demo 开发和企业数据治理中实现价值。虽存在安全、场景适配等局限,但通过‘人机协作’模式,能显著降低编码门槛、提升开发效率,成为数智融合背景下,推动软件开发从‘人工编码’迈向‘数据驱动人机共创’的关键支撑。
许家辉 审核:姚一杰